
tg-me.com/knowledge_accumulator/179
Last Update:
Structurally Flexible Neural Networks: Evolving the Building Blocks for General Agents [2024]
Наткнулся на ещё одну работу, в которой обучают модель-алгоритм. Её используют тут же для решения RL-задач, с результатами, по графикам сильно превосходящими VSML.
Авторы придерживаются тех же базовых принципов - мало мета-параметров (обучающихся генетикой), большое скрытое состояние. Различие в том, в какую именно архитектуру всё это запаковано. У VSML это несколько "слоёв" LSTM, сцепленных, как обычная нейронная сеть, со связями вперёд и назад.
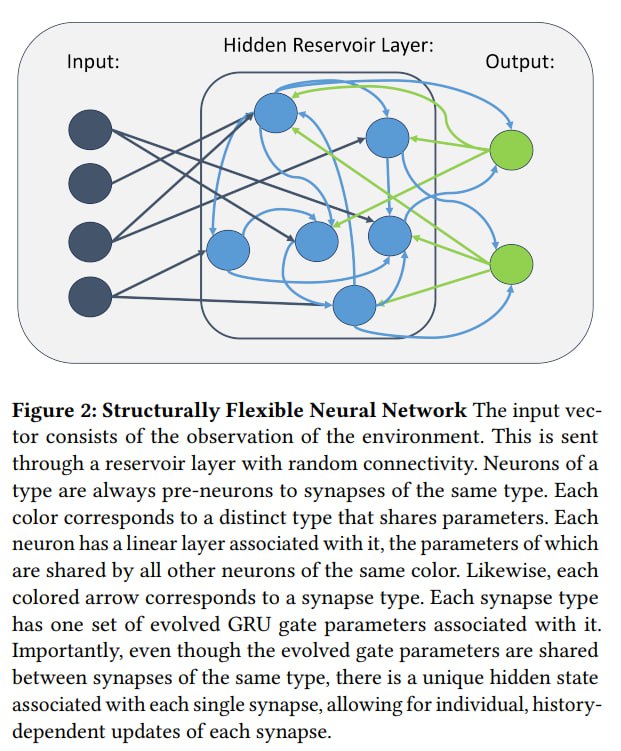
В данной работе авторы используют более гибкую схему:
1) Есть 3 вида нейронов - входные, скрытые и выходные
2) Каждый входной нейрон может быть связан с каждым скрытым, каждый скрытый с каждым выходным
3) Перед началом обучения (то есть внутри эволюционной итерации) сэмплируются бинарные маски IxH и HxO, обозначающие наличие связи между каждым input и hidden, а также между каждым hidden и output.
А что, собственно, обучается? Чем является в данном случае "нейрон"?
Каждый нейрон принимает на вход векторы сигналов, складывает их и получает свой "Pre-neuron". Далее он домножается поэлементно на вектор w и получается post-neuron. После этого pre-neuron, post-neuron и награда из среды подаются в GRU, которая выдаёт дельту для вектора w.
Вектор w у каждого нейрона свой, а вот веса GRU у всех скрытых нейронов одинаковые. То же и с входными, и с выходными группами, но у каждой группы своя GRU.
Мне лично нравится, что такая плотно связанная сеть нейронов позволяет легко пробрасывать информацию по всей модели и быстрее обучаться своей задаче. Она содержит ещё меньше априорных допущений, чем предыдущий подход, что соответствует выводам из Bitter Lesson. Прорыв в итоге совершит подход, лучше всего балансирующий между гибкостью и эффективностью исполнения на современных GPU - иначе он падёт жертвой hardware lottery.
Из минусов статьи - нет кода, нет meta-testing (хотя сомнений в успехе у меня нет), нет описания затраченных на обучение ресурсов.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/179